

OCR - Image Reader
243 個評分
)
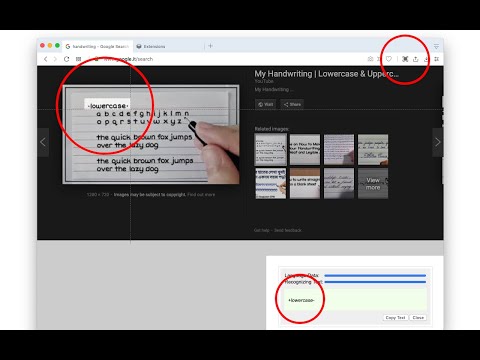
總覽
A powerful optical character recognition (OCR) extension to capture and convert images to text
This extension adds a toolbar button to your browser to perform OCR. When this action button is pressed, it allows the user to select a region in the currently active window. The extension captures the area and tries to recognize text inside this region using the internal powerful OCR engine (Tesseract engine). This extension uses the "tesseract.js" library that supports more than 100 languages, automatic text orientation, and script detection. This extension loads the JS library on the page and removes it when you are done. This way, there is no long-term resource usage. Engines: Tesseract: Only extracts plain text from images and doesn't preserve formatting IBM Granite-Docling: it can accurately interpret headings, lists, styles (bold, italics), tables, and mathematical equations. Notes: 1. On the first run, the extension might take a few minutes to fetch the training data from the internet. Since this resource is cached, all subsequent calls are going to be fast. 2. Optical character recognition (OCR) is slow, so this extension displays a progress bar for each detection module. 3. This extension does the OCR process offline. There is no server-side interaction. It only fetches the language training database once. 4. This tool can be used to extract the text content out of images, PDF documents, Powerpoint slides, or extract the content of a web page when user-section is forbidden. 5. If the text extraction confidence is low, the extension inverts the image and retries (particularly useful on the dark theme) 6. If the text extraction is not accurate, you can modify the image and drop it into the interface to retry. Change Logs: Version 0.2.4: Supports browser-level page zooming and OS-level screen zooming Adds image language detection (still beta) (slow operation)
4.1 分 (滿分 5 分)243 個評分
詳細資料
- 版本0.5.0
- 已更新2025年10月13日
- 提供者brian.girko
- 大小7.76MiB
- 語言English
- 開發人員
電子郵件
brian.girko@gmail.com - 非交易商這位開發人員並未表明自己是交易商。歐盟地區的消費者請注意,消費者權利不適用於你和這位開發人員之間簽訂的合約。
隱私權

這位開發者就你的資料做出下列聲明:
- 除經核准的用途外,不會將你的資料販售給第三方
- 不會基於與商品核心功能無關的目的,使用或轉移資料
- 不會為了確認信用度或基於貸款目的,使用或轉移資料
支援
如有疑問或建議,請前往開發人員的支援網站