


Огляд
Easily get words out of an image with OCR engine!
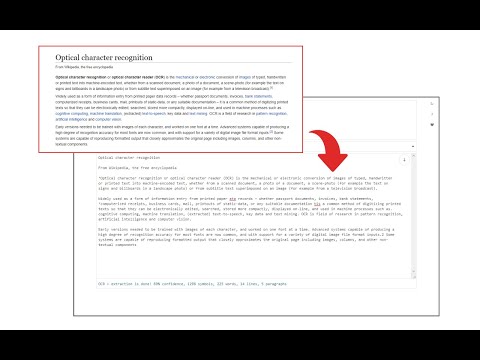
Image Reader (OCR) extension helps you easily get words out of any image. It uses two different open-source OCR engines. The 1st engine is called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. The 2nd engine, called Granite Docling, is developed by IBM (https://huggingface.co/ibm-granite/granite-docling-258M). Please note that when you choose IBM Granite Docling, the app needs to download training data (~1200MB) for the AI engine. So please be patient while it is loading. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR engine and language. For Tesseract, the default OCR language is set to English. For Granite Docling, you do not need to set a language; just select the desired backend (CPU or GPU) and wait for the app to load completely. Note: For the Tesseract OCR engine, this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. For the IBM Granite Docling, it uses "https://huggingface.co/onnx-community/granite-docling-258M-ONNX" to fetch training data required for the OCR operation. Both language data packs are very large and cannot be included in the addon package. To report bugs, please fill out the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
3,6 з 527 оцінок
Деталі
- Версія0.2.0
- Оновлено10 листопада 2025 р.
- Розробник:Sevina
- Розмір13.19MiB
- МовиEnglish
- Розробник
Електронна пошта
sevina.lucia@gmail.com - Не продавецьЦей розробник не ідентифікував себе як продавець. Зверніть увагу, що права споживачів у Європейському Союзі не поширюються на контракти з цим розробником.
Конфіденційність
Цей розробник заявляє, що ваші дані:
- не продаються третім особам (за винятком дозволених випадків)
- не використовуються й не передаються для цілей, що не пов’язані з основними функціями продукту
- не використовуються й не передаються для визначення кредитоспроможності або в цілях кредитування
Підтримка
Із запитаннями, пропозиціями й проблемами звертайтеся на сайт підтримки розробника.