


ภาพรวม
Easily get words out of an image with OCR engine!
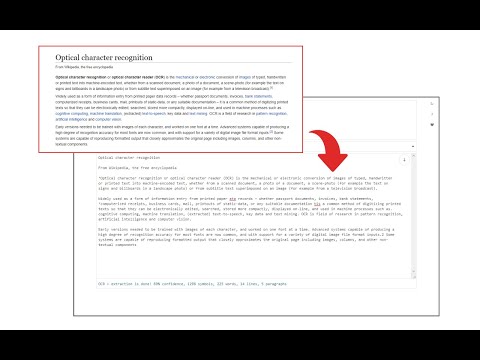
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
3.6 จาก 5 คะแนนการให้คะแนน 27 รายการ
รายละเอียด
- รุ่น0.1.9
- อัปเดตแล้ว1 กันยายน 2568
- นำเสนอโดยSevina
- ขนาด7.53MiB
- ภาษาEnglish
- นักพัฒนาซอฟต์แวร์
อีเมล
sevina.lucia@gmail.com - ไม่ใช่ผู้ค้านักพัฒนาซอฟต์แวร์รายนี้ไม่ได้ระบุว่าตัวเองเป็นผู้ค้า สำหรับผู้บริโภคในสหภาพยุโรป โปรดทราบว่าสิทธิของผู้บริโภคไม่มีผลกับสัญญาระหว่างคุณกับนักพัฒนาซอฟต์แวร์รายนี้
ความเป็นส่วนตัว
นักพัฒนาซอฟต์แวร์รายนี้ประกาศว่าข้อมูลของคุณจะ
- ไม่ถูกขายไปยังบุคคลที่สามหากไม่ใช่ Use Case ที่ได้รับอนุมัติ
- ไม่ถูกใช้หรือถูกโอนเพื่อวัตถุประสงค์ที่ไม่เกี่ยวข้องกับฟังก์ชันการทำงานหลักของรายการ
- ไม่ถูกใช้หรือถูกโอนเพื่อพิจารณาความน่าเชื่อถือทางเครดิตหรือเพื่อวัตถุประสงค์การให้สินเชื่อ
สนับสนุน
โปรดไปที่เว็บไซต์สนับสนุนของนักพัฒนาซอฟต์แวร์ หากมีข้อสงสัย ต้องการขอคำแนะนำ หรือพบปัญหาใดๆ