


Áttekintés
Easily get words out of an image with OCR engine!
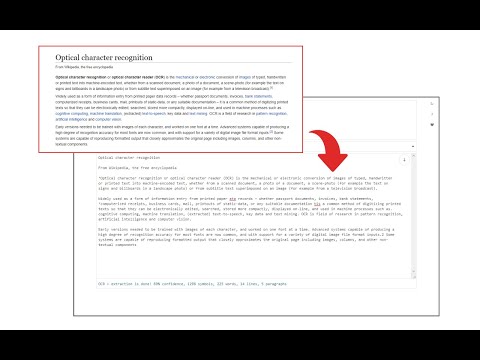
Image Reader (OCR) extension helps you easily get words out of any image. It uses two different open-source OCR engines. The 1st engine is called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. The 2nd engine, called Granite Docling, is developed by IBM (https://huggingface.co/ibm-granite/granite-docling-258M). Please note that when you choose IBM Granite Docling, the app needs to download training data (~1200MB) for the AI engine. So please be patient while it is loading. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR engine and language. For Tesseract, the default OCR language is set to English. For Granite Docling, you do not need to set a language; just select the desired backend (CPU or GPU) and wait for the app to load completely. Note: For the Tesseract OCR engine, this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. For the IBM Granite Docling, it uses "https://huggingface.co/onnx-community/granite-docling-258M-ONNX" to fetch training data required for the OCR operation. Both language data packs are very large and cannot be included in the addon package. To report bugs, please fill out the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
5/3,627 értékelés
Részletek
- Verziók0.2.0
- Frissítve2025. november 10.
- Forrás:Sevina
- Méret13.19MiB
- NyelvekEnglish
- Fejlesztő
E-mail
sevina.lucia@gmail.com - Nem kereskedőEz a fejlesztő nem azonosította magát kereskedőként. Felhívjuk az Európai Unióban élő fogyasztók figyelmét arra, hogy a fogyasztói jogok nem érvényesek az Ön és a fejlesztő közötti szerződésekre.
Adatvédelem
Ez a fejlesztő kijelenti, hogy az Ön adatai:
- Nem kerülnek értékesítésre harmadik félnek az engedélyezett használati eseteken kívül.
- nem lesznek felhasználva vagy átadva olyan célokból, amelyek nem kapcsolódnak az elem alapvető működéséhez;
- nem lesznek felhasználva vagy átadva hitelképesség-meghatározási vagy kölcsönzési célokra.
Támogatás
A kérdésekkel, javaslatokkal vagy problémákkal kapcsolatos segítségért keresse fel a fejlesztő ügyfélszolgálati webhelyét.