


סקירה כללית
Easily get words out of an image with OCR engine!
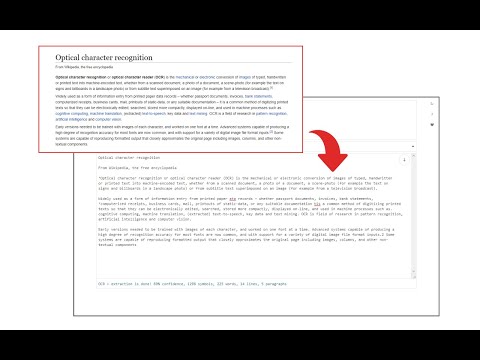
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
3.7 מתוך 526 דירוגים
Google לא מאמתת ביקורות. מידע נוסף על תוצאות וביקורות
פרטים
- גרסה0.1.8
- עדכון אחרון30 בדצמבר 2024
- מאתSevina
- גודל7.53MiB
- שפותEnglish
- מפתח
אימייל
sevina.lucia@gmail.com - לא עסקהמפַתח הזה לא ציין שהפעילות שלו נעשית במסגרת עסק. חשוב לשים לב: זכויות הצרכן לא חלות על חוזים בין צרכנים שנמצאים באיחוד האירופי לבין המפַתח הזה.
פרטיות
המפַתח הזה מצהיר כי הנתונים שלך:
- לא יימכרו לצדדים שלישיים, למעט בתרחישים שאושרו
- לא משמשים או מועברים למטרות שאינן קשורות לפונקציונליות המרכזית של הפריט
- לא משמשים או מועברים לצורך קביעת מצב אשראי או לצורכי הלוואה
תמיכה
באתר התמיכה של המפתח ניתן לקבל עזרה לגבי שאלות, הצעות או בעיות.